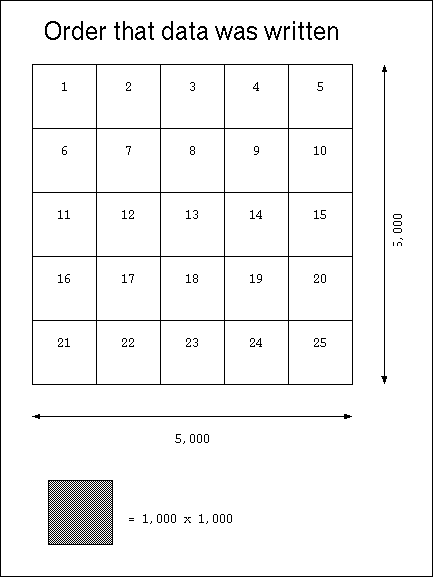
Fig 1: Write-order of Output Blocks
This is the results of studying the chunked layout policy in HDF5. A 1000 by 1000 array of integers was written to a file dataset extending the dataset with each write to create, in the end, a 5000 by 5000 array of 4-byte integers for a total data storage size of 100 million bytes.
After the array was written, it was read back in blocks that were 500 by 500 bytes in row major order (that is, the top-left quadrant of output block one, then the top-right quadrant of output block one, then the top-left quadrant of output block 2, etc.).
I tried to answer two questions:
I started with chunk sizes that were multiples of the read block size or k*(500, 500).
| Chunk Size (elements) | Meta Data Overhead (ppm) | Raw Data Overhead (ppm) |
|---|---|---|
| 500 by 500 | 85.84 | 0.00 |
| 1000 by 1000 | 23.08 | 0.00 |
| 5000 by 1000 | 23.08 | 0.00 |
| 250 by 250 | 253.30 | 0.00 |
| 499 by 499 | 85.84 | 205164.84 |
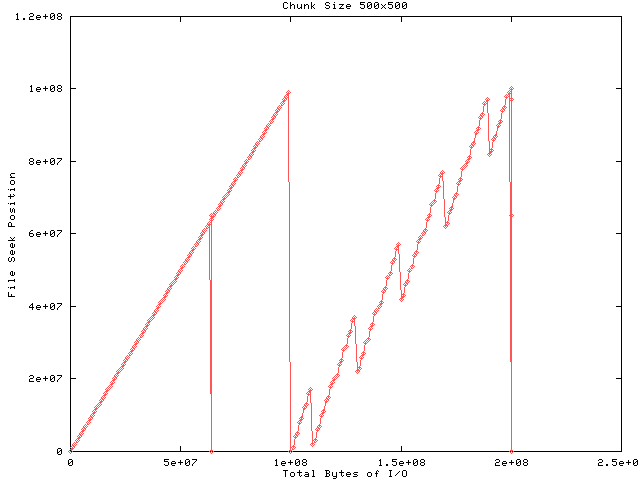
The first half of Figure 2 shows output to the file while the second half shows input. Each dot represents a file-level I/O request and the lines that connect the dots are for visual clarity. The size of the request is not indicated in the graph. The output block size is four times the chunk size which results in four file-level write requests per block for a total of 100 requests. Since file space for the chunks was allocated in output order, and the input block size is 1/4 the output block size, the input shows a staircase effect. Each input request results in one file-level read request. The downward spike at about the 60-millionth byte is probably the result of a cache miss for the B-tree and the downward spike at the end is probably a cache flush or file boot block update.
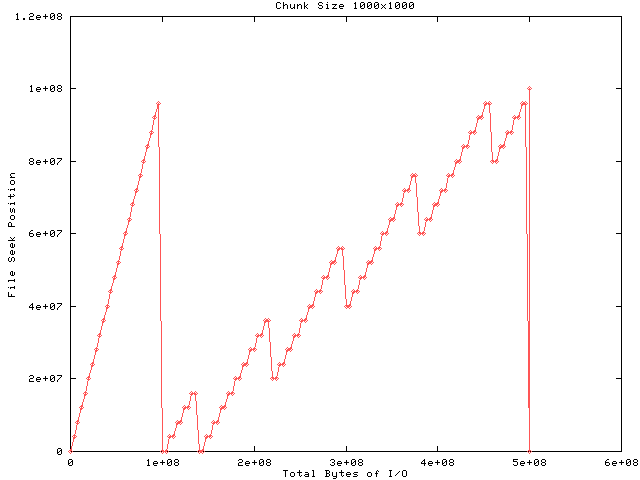
In this test I increased the chunk size to match the output chunk size and one can see from the first half of the graph that 25 file-level write requests were issued, one for each output block. The read half of the test shows that four times the amount of data was read as written. This results from the fact that HDF5 must read the entire chunk for any request that falls within that chunk, which is done because (1) if the data is compressed the entire chunk must be decompressed, and (2) the library assumes that a chunk size was chosen to optimize disk performance.
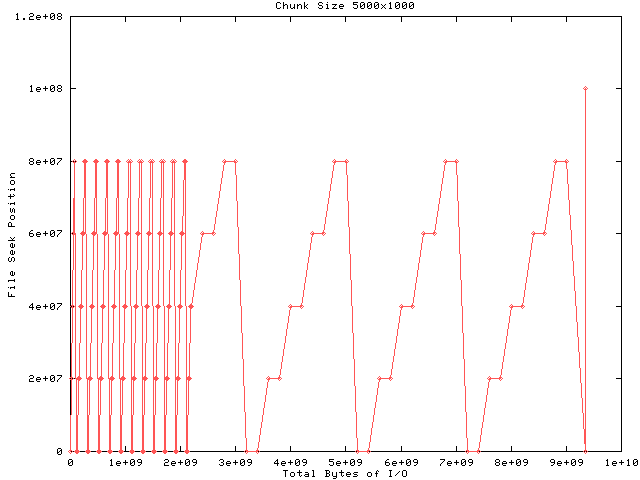
Increasing the chunk size further results in even worse performance since both the read and write halves of the test are re-reading and re-writing vast amounts of data. This proves that one should be careful that chunk sizes are not much larger than the typical partial I/O request.
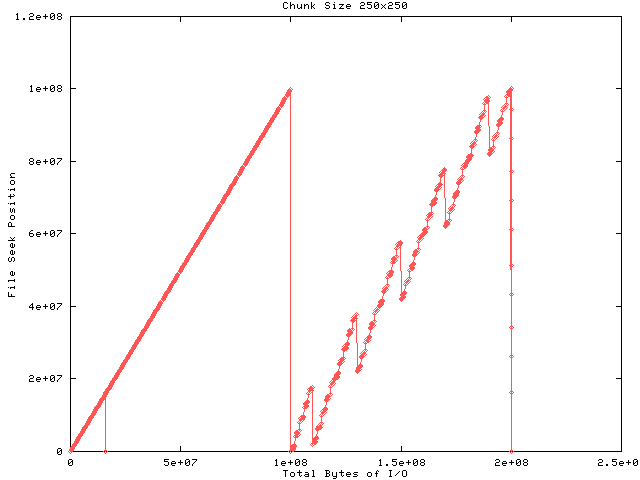
If the chunk size is decreased then the amount of data transfered between the disk and library is optimal for no caching, but the amount of meta data required to describe the chunk locations increases to 250 parts per million. One can also see that the final downward spike contains more file-level write requests as the meta data is flushed to disk just before the file is closed.
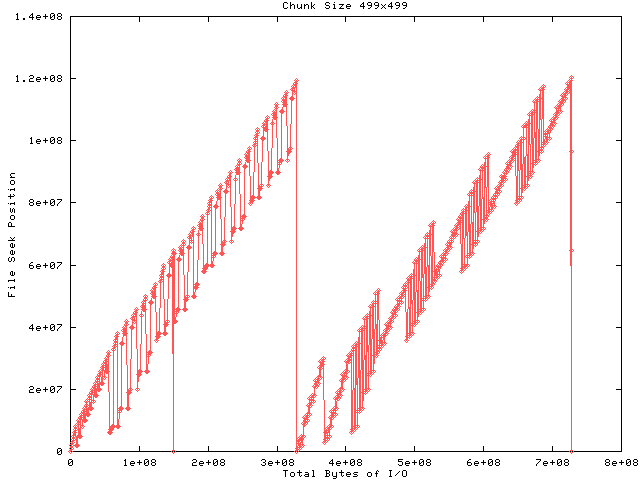
This test shows the result of choosing a chunk size which is close to the I/O block size. Because the total size of the array isn't a multiple of the chunk size, the library allocates an extra zone of chunks around the top and right edges of the array which are only partially filled. This results in 20,516,484 extra bytes of storage, a 20% increase in the total raw data storage size. But the amount of meta data overhead is the same as for the 500 by 500 test. In addition, the mismatch causes entire chunks to be read in order to update a few elements along the edge or the chunk which results in a 3.6-fold increase in the amount of data transfered.