An HDF5 attribute is a small metadata object describing the nature and/or intended usage of a primary data object. A primary data object may be a dataset, group, or committed datatype.
Attributes are assumed to be very small as data objects go, so storing them as standard HDF5 datasets would be quite inefficient. HDF5 attributes are therefore managed through a special attributes interface, H5A, which is designed to easily attach attributes to primary data objects as small datasets containing metadata information and to minimize storage requirements.
Consider, as examples of the simplest case, a set of laboratory readings taken under known temperature and pressure conditions of 18.0 degrees celsius and 0.5 atmospheres, respectively. The temperature and pressure stored as attributes of the dataset could be described as the following name/value pairs:
temp=18.0 pressure=0.5
While HDF5 attributes are not standard HDF5 datasets, they have much in common:
But there are some very important differences:
The “Special Issues” section below describes how to handle attributes that are large in size and how to handle large numbers of attributes.
This chapter discusses or lists the following:
In the following discussions, attributes are generally attached to datasets. Attributes attached to other primary data objects, i.e., groups or committed datatypes, are handled in exactly the same manner.
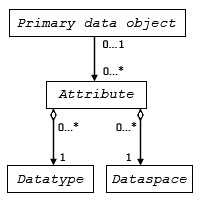
The figure below shows the UML model for an HDF5 attribute and its associated dataspace and datatype.
|
|
| Figure 1. The UML model for an HDF5 attribute |
Creating an attribute is similar to creating a dataset. To create an attribute, the application must specify the object to which the attribute is attached, the datatype and dataspace of the attribute data, and the attribute creation property list.
The following steps are required to create and write an HDF5 attribute:
The following steps are required to open and read/write an existing attribute. Since HDF5 attributes allow no partial I/O, you need specify only the attribute and the attribute’s memory datatype to read it:
Functions that can be used with attributes (H5A functions) and functions that can be used with property lists (H5P functions) are listed below.
| Function Listing 1. Attribute functions (H5A) | |
|
C Function Fortran Function |
Purpose |
H5Acreate
h5acreate_f |
Creates a dataset as an attribute of another group, dataset, or committed datatype. The C function is a macro: see “API Compatibility Macros in HDF5.” |
H5Acreate_by_name
h5acreate_by_name_f |
Creates an attribute attached to a specified object. |
H5Aexists
h5aexists_f |
Determines whether an attribute with a given name exists on an object. |
H5Aexists_by_name
h5aexists_by_name_f |
Determines whether an attribute with a given name exists on an object. |
H5Aclose
h5aclose_f |
Closes the specified attribute. |
H5Adelete
h5adelete_f |
Deletes an attribute. |
H5Adelete_by_idx
h5adelete_by_idx_f |
Deletes an attribute from an object according to index order. |
H5Adelete_by_name
h5adelete_by_name_f |
Removes an attribute from a specified location. |
H5Aget_create_plist
h5aget_create_plist_f |
Gets an attribute creation property list identifier. |
H5Aget_info
h5aget_info_f |
Retrieves attribute information by attribute identifier. |
H5Aget_info_by_idx
h5aget_info_by_idx_f |
Retrieves attribute information by attribute index position. |
H5Aget_info_by_name
h5aget_info_by_name_f |
Retrieves attribute information by attribute name. |
H5Aget_name
h5aget_name_f |
Gets an attribute name. |
H5Aget_name_by_idx
h5aget_name_by_idx_f |
Gets an attribute name by attribute index position. |
H5Aget_space
h5aget_space_f |
Gets a copy of the dataspace for an attribute. |
H5Aget_storage_size
h5aget_storage_size_f |
Returns the amount of storage required for an attribute. |
H5Aget_type
h5aget_type_f |
Gets an attribute datatype. |
H5Aiterate
(none) |
Calls a user’s function for each attribute attached to a data object. The C function is a macro: see “API Compatibility Macros in HDF5.” |
H5Aiterate_by_name
(none) |
Calls user-defined function for each attribute on an object. |
H5Aopen
h5aopen_f |
Opens an attribute for an object specified by object identifier and attribute name. |
H5Aopen_by_idx
h5aopen_by_idx_f |
Opens an existing attribute that is attached to an object specified by location and name. |
H5Aopen_by_name
h5aopen_by_name_f |
Opens an attribute for an object by object name and attribute name. |
H5Aread
h5aread_f |
Reads an attribute. |
H5Arename
h5arename_f |
Renames an attribute. |
H5Arename_by_name
h5arename_by_name_f |
Renames an attribute. |
H5Awrite
H5awrite_f |
Writes an attribute. |
| Function Listing 2. Attribute creation property list functions (H5P) | |
|
C Function Fortran Function |
Purpose |
H5Pset_char_encoding
|
Sets the character encoding used to encode a string. Use to set ASCII or UTF-8 character encoding for object names. |
H5Pget_char_encoding
|
Retrieves the character encoding used to create a string. |
H5Pget_attr_creation_order
|
Retrieves tracking and indexing settings for attribute creation order. |
H5Pget_attr_phase_change
|
Retrieves attribute storage phase change thresholds. |
H5Pset_attr_creation_order
|
Sets tracking and indexing of attribute creation order. |
H5Pset_attr_phase_change
|
Sets attribute storage phase change thresholds. |
An attribute has two parts: name and value(s)
HDF5 attributes are sometimes discussed as name/value pairs
in the form name=value.
An attribute’s name is a null-terminated ASCII character string. Each attribute attached to an object has a unique name.
The value portion of the attribute contains one or more data elements of the same datatype.
HDF5 attributes have all the characteristics of HDF5 datasets except that there is no partial I/O capability. In other words, attributes can be written and read only in full with no sub-setting.
If attributes are used in an HDF5 file,
these functions will be employed: H5Acreate,
H5Awrite, and H5Aread.
H5Acreate and H5Awrite are used together
to place the attribute in the file.
If an attribute is to be used and is not currently in memory,
H5Aread generally comes into play
usually in concert with one each of the
H5Aget_* and H5Aopen_* functions.
H5Acreate:
hid_t H5Acreate (hid_t loc_id,
const char *name,
hid_t type_id,
hid_t space_id,
hid_t create_plist,
hid_t access_plist)
loc_id identifies the object (dataset, group, or committed
datatype) to which the attribute is to be attached.
name,
type_id,
space_id, and
create_plist
convey, respectively, the attribute’s name, datatype, dataspace,
and attribute creation property list.
The attribute’s name must be locally unique:
it must be unique within the context of the object
to which it is attached.
H5Acreate creates the attribute in memory.
The attribute does not exist in the file until H5Awrite
writes it there.
H5Awrite or H5Aread, respectively:
herr_t H5Awrite (hid_t attr_id,
hid_t mem_type_id,
const void *buf)
herr_t H5Aread (hid_t attr_id,
hid_t mem_type_id,
void *buf)
attr_id identifies the attribute while
mem_type_id identifies the in-memory datatype
of the attribute data.
H5Awrite writes the attribute data
from the buffer buf to the file.
H5Aread reads attribute data from the file into
buf.
The HDF5 Library converts the metadata between the
in-memory datatype, mem_type_id, and
the in-file datatype, defined when the attribute was created,
without user intervention.
Attributes can be accessed by name or index value. The use of an index value makes it possible to iterate through all of the attributes associated with a given object.
To access an attribute by its name,
use the H5Aopen_by_name function. H5Aopen_by_name
returns an attribute identifier that can then be used by any function that
must access an attribute such as H5Aread.
Use the function H5Aget_name to determine an attribute’s name.
To access an attribute by its index value
, use the H5Aopen_by_idx function. To determine an
attribute index value when it is not already known,
use the H5Oget_infofunction. H5Aopen_by_idx is
generally used in the course of opening several attributes for later access.
Use H5Aiterate if the intent is to
perform the same operation on every attribute attached to an object.
In the course of working with HDF5 attributes, one may need to obtain any of several pieces of information:
H5Aget_name with an attribute identifier,
attr_id:
ssize_t H5Aget_name (hid_t attr_id, size_t buf_size,
char *buf)
As with other attribute functions, attr_id
identifies the attribute; buf_size defines the size of the
buffer; and buf is the buffer to which the attribute’s name
will be read.
If the length of the attribute name, and hence the value required for
buf_size, is unknown, a first call to
H5Aget_name will return that size. If the value of
buf_size used in that first call is too small,
the name will simply be truncated in buf.
A second H5Aget_name call can then be used to retrieve the
name in an appropriately-sized buffer.
H5Aget_space or
H5Aget_type, respectively:
hid_t H5Aget_space (hid_t attr_id)
hid_t H5Aget_type (hid_t attr_id)
H5Aget_space returns the dataspace identifier
for the attribute attr_id.
H5Aget_type returns the datatype identifier
for the attribute attr_id.
H5Oget_info function.
The function signature is below.
herr_t H5Oget_info( hid_t object_id, H5O_info_t *object_info )
The number of attributes will be returned in the object_info
buffer. This is generally the preferred first step in determining attribute
index values. If the call returns N, the
attributes attached to the object object_id
have index values of 0 through N
-1.
It is sometimes useful to be able to perform the identical operation across all of the attributes attached to an object. At the simplest level, you might just want to open each attribute. At a higher level, you might wish to perform a rather complex operation on each attribute as you iterate across the set.
H5Aiterate:
herr_t H5Aiterate (hid_t obj_id,
H5_index_t index_type,
H5_iter_order_t order,
hsize_t *n,
H5A_operator2_t op,
void *op_data)
H5Aiterate successively marches across all of the
attributes attached to the object specified in
loc_id, performing the operation(s)
specified in op_func with the data
specified in op_data on each attribute.
When H5Aiterate is called,
index contains the index of the attribute
to be accessed in this call.
When H5Aiterate returns, index
will contain the index of the next attribute.
If the returned index is the null pointer,
then all attributes have been processed, and the iterative process
is complete.
op_func is a user-defined operation
that adheres to the H5A_operator_t prototype.
This prototype and certain requirements imposed on the operator’s
behavior are described in the H5Aiterate entry
in the
HDF5 Reference Manual.
op_data is also user-defined to meet
the requirements of op_func.
Beyond providing a parameter with which to pass this data,
HDF5 provides no tools for its management and imposes no restrictions.
Once an attribute has outlived its usefulness or is no longer appropriate, it may become necessary to delete it.
H5Adelete:
herr_t H5Adelete (hid_t loc_id,
const char *name)
H5Adelete removes the attribute
name from the group, dataset, or
committed datatype specified in loc_id.
H5Adelete must not be called if there are
any open attribute identifiers on the object
loc_id. Such a call can cause
the internal attribute indexes to change; future writes to
an open attribute would then produce unintended results.
As is the case with all HDF5 objects, once access to an attribute
it is no longer needed, that attribute must be closed.
It is best practice to close it as soon as practicable;
it is mandatory that it be closed prior to the H5close
call closing the HDF5 Library.
H5Aclose:
herr_t H5Aclose (hid_t attr_id)
H5Aclose closes the specified attribute by terminating
access to its identifier, attr_id.
Some special issues for attributes are discussed below.
The dense attribute storage scheme was added in version 1.8 so that datasets, groups, and committed datatypes that have large numbers of attributes could be processed more quickly.
Attributes start out being stored in an object's header. This is known as compact storage. See the “Datasets” chapter for more information on compact, contiguous, and chunked storage.
As the number of attributes grows, attribute-related performance
slows. To improve performance, dense attribute storage can be initiated
with the H5Pset_attr_phase_change function. See the
HDF5 Reference Manual for more information.
When dense attribute storage is enabled, a threshold is defined for the number of attributes kept in compact storage. When the number is exceeded, the library moves all of the attributes into dense storage at another location. The library handles the movement of attributes and the pointers between the locations automatically. If some of the attributes are deleted so that the number falls below the threshold, then the attributes are moved back to compact storage by the library.
The improvements in performance from using dense attribute storage are the result of holding attributes in a heap and indexing the heap with a B-tree.
Note that there are some disadvantages to using dense attribute storage. One is that this is a new feature. Datasets, groups, and committed datatypes that use dense storage cannot be read by applications built with earlier versions of the library. Another disadvantage is that attributes in dense storage cannot be compressed.
We generally consider the maximum size of an attribute to be 64K bytes. The library has two ways of storing attributes larger than 64K bytes: in dense attribute storage or in a separate dataset. Using dense attribute storage is described in this section, and storing in a separate dataset is described in the next section.
To use dense attribute storage to store large attributes, set the
number of attributes that will be stored in compact storage to 0 with
the H5Pset_attr_phase_change function. This will force
all attributes to be put into dense attribute storage and will avoid
the 64KB size limitation for a single attribute in compact attribute
storage.
In addition to dense attribute storage (see above), a large attribute can be stored in a separate dataset. In the figure below, DatasetA holds an attribute that is too large for the object header in Dataset1. By putting a pointer to DatasetA as an attribute in Dataset1, the attribute becomes available to those working with Dataset1.
This way of handling large attributes can be used in situations where backward compatibility is important and where compression is important. Applications built with versions before 1.8.x can read large attributes stored in separate datasets. Datasets can be compressed while attributes cannot.
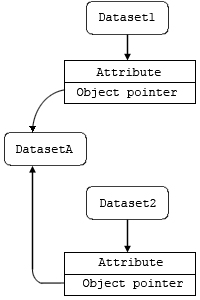 |
Figure 2. A large or shared HDF5 attribute
and its associated dataset(s)
DatasetA is an attribute of
Dataset1 that is too large
to store in Dataset1's header.
DatasetA is associated with Dataset1
by means of an object reference pointer attached as an
attribute to Dataset1. The attribute in
DatasetA can be shared among multiple datasets by
means of additional object reference pointers attached
to additional datasets. |
Attributes written and managed through the H5A interface cannot be shared. If shared attributes are required, they must be handled in the manner described above for large attributes and illustrated in the figure above.
While any ASCII or UTF-8 character may be used in the name given to an attribute, it is usually wise to avoid the following kinds of characters:
NULL can be used within a name, but HDF5 names are terminated with a NULL: whatever comes after the NULL will be ignored by HDF5.
The use of ASCII or UTF-8 characters is determined by the character
encoding property. See H5Pset_char_encoding in the
HDF5 Reference Manual.
HDF5 attributes have all the characteristics of HDF5 datasets except the following: