The datatype interface provides a mechanism to describe the storage format of individual data points of a data set and is hopefully designed in such a way as to allow new features to be easily added without disrupting applications that use the datatype interface. A dataset (the H5D interface) is composed of a collection or raw data points of homogeneous type organized according to the data space (the H5S interface).
A datatype is a collection of datatype properties, all of which can be stored on disk, and which when taken as a whole, provide complete information for data conversion to or from that datatype. The interface provides functions to set and query properties of a datatype.
A data point is an instance of a datatype, which is an instance of a type class. We have defined a set of type classes and properties which can be extended at a later time. The atomic type classes are those which describe types which cannot be decomposed at the datatype interface level; all other classes are compound.
The functions defined in this section operate on datatypes as
a whole. New datatypes can be created from scratch or copied
from existing datatypes. When a datatype is no longer needed
its resources should be released by calling H5Tclose().
Datatypes come in two flavors: named datatypes and transient
datatypes. A named datatype is stored in a file while the
transient flavor is independent of any file. Named datatypes
are always read-only, but transient types come in three
varieties: modifiable, read-only, and immutable. The difference
between read-only and immutable types is that immutable types
cannot be closed except when the entire library is closed (the
predefined types like H5T_NATIVE_INT are immutable
transient types).
hid_t H5Tcreate (H5T_class_t class, size_t
size)
H5T_COMPOUND to create a new empty compound
datatype where size is the total size in bytes of an
instance of this datatype. Other datatypes are created with
H5Tcopy(). All functions that return datatype
identifiers return a negative value for failure.
hid_t H5Topen (hid_t location, const char
*name)
H5Tclose() to
release resources. The named datatype returned by this
function is read-only or a negative value is returned for
failure. The location is either a file or group
identifier.
herr_t H5Tcommit (hid_t location, const char
*name, hid_t type)
htri_t H5Tcommitted (hid_t type)
H5Dget_type() are able to share
the datatype with other datasets in the same file.
hid_t H5Tcopy (hid_t type)
herr_t H5Tclose (hid_t type)
htri_t H5Tequal (hid_t type1, hid_t
type2)
TRUE, otherwise it returns FALSE (an
error results in a negative return value).
herr_t H5Tlock (hid_t type)
H5close() or by normal program termination).
An atomic type is a type which cannot be decomposed into smaller units at the API level. All atomic types have a common set of properties which are augmented by properties specific to a particular type class. Some of these properties also apply to compound datatypes, but we discuss them only as they apply to atomic datatypes here. The properties and the functions that query and set their values are:
H5T_class_t H5Tget_class (hid_t type)
H5T_INTEGER, H5T_FLOAT, H5T_TIME, H5T_STRING, or
H5T_BITFIELD. This property is read-only and is set
when the datatype is created or copied (see
H5Tcreate(), H5Tcopy()). If this
function fails it returns H5T_NO_CLASS which has
a negative value (all other class constants are non-negative).
size_t H5Tget_size (hid_t type)
herr_t H5Tset_size (hid_t type, size_t
size)
offset property is
decremented a bit at a time. If the offset reaches zero and
the significant part of the data still extends beyond the edge
of the datatype then the precision property is
decremented a bit at a time. Decreasing the size of a
datatype may fail if the H5T_FLOAT bit fields would
extend beyond the significant part of the type. Adjusting the
size of an H5T_STRING automatically adjusts the
precision as well. On error, H5Tget_size()
returns zero which is never a valid size.
H5T_order_t H5Tget_order (hid_t type)
herr_t H5Tset_order (hid_t type, H5T_order_t
order)
H5T_ORDER_LE. If the bytes are in the oposite
order then they are said to be big-endian or
H5T_ORDER_BE. Some datatypes have the same byte
order on all machines and are H5T_ORDER_NONE
(like character strings). If H5Tget_order()
fails then it returns H5T_ORDER_ERROR which is a
negative value (all successful return values are
non-negative).
size_t H5Tget_precision (hid_t type)
herr_t H5Tset_precision (hid_t type, size_t
precision)
short on a Cray
is 32 significant bits in an eight-byte field. The
precision property identifies the number of
significant bits of a datatype and the offset
property (defined below) identifies its location. The
size property defined above represents the entire
size (in bytes) of the datatype. If the precision is
decreased then padding bits are inserted on the MSB side of
the significant bits (this will fail for
H5T_FLOAT types if it results in the sign,
mantissa, or exponent bit field extending beyond the edge of
the significant bit field). On the other hand, if the
precision is increased so that it "hangs over" the edge of the
total size then the offset property is
decremented a bit at a time. If the offset
reaches zero and the significant bits still hang over the
edge, then the total size is increased a byte at a time. The
precision of an H5T_STRING is read-only and is
always eight times the value returned by
H5Tget_size(). H5Tget_precision()
returns zero on failure since zero is never a valid precision.
size_t H5Tget_offset (hid_t type)
herr_t H5Tset_offset (hid_t type, size_t
offset)
precision property defines the number
of significant bits, the offset property defines
the location of those bits within the entire datum. The bits
of the entire data are numbered beginning at zero at the least
significant bit of the least significant byte (the byte at the
lowest memory address for a little-endian type or the byte at
the highest address for a big-endian type). The
offset property defines the bit location of the
least signficant bit of a bit field whose length is
precision. If the offset is increased so the
significant bits "hang over" the edge of the datum, then the
size property is automatically incremented. The
offset is a read-only property of an H5T_STRING
and is always zero. H5Tget_offset() returns zero
on failure which is also a valid offset, but is guaranteed to
succeed if a call to H5Tget_precision() succeeds
with the same arguments.
herr_t H5Tget_pad (hid_t type, H5T_pad_t
*lsb, H5T_pad_t *msb)
herr_t H5Tset_pad (hid_t type, H5T_pad_t
lsb, H5T_pad_t msb)
precision and offset properties
are called padding. Padding falls into two
categories: padding in the low-numbered bits is lsb
padding and padding in the high-numbered bits is msb
padding (bits are numbered according to the description for
the offset property). Padding bits can always be
set to zero (H5T_PAD_ZERO) or always set to one
(H5T_PAD_ONE). The current pad types are returned
through arguments of H5Tget_pad() either of which
may be null pointers.
Integer atomic types (class=H5T_INTEGER)
describe integer number formats. Such types include the
following information which describes the type completely and
allows conversion between various integer atomic types.
H5T_sign_t H5Tget_sign (hid_t type)
herr_t H5Tset_sign (hid_t type, H5T_sign_t
sign)
H5T_SGN_2) or unsigned
(H5T_SGN_NONE). Whether data is signed or not
becomes important when converting between two integer
datatypes of differing sizes as it determines how values are
truncated and sign extended.
The library supports floating-point atomic types
(class=H5T_FLOAT) as long as the bits of the
exponent are contiguous and stored as a biased positive number,
the bits of the mantissa are contiguous and stored as a positive
magnitude, and a sign bit exists which is set for negative
values. Properties specific to floating-point types are:
herr_t H5Tget_fields (hid_t type, size_t
*spos, size_t *epos, size_t
*esize, size_t *mpos, size_t
*msize)
herr_t H5Tset_fields (hid_t type, size_t
spos, size_t epos, size_t esize,
size_t mpos, size_t msize)
precision and offset
properties). The sign bit is always of length one and none of
the fields are allowed to overlap. When expanding a
floating-point type one should set the precision first; when
decreasing the size one should set the field positions and
sizes first.
size_t H5Tget_ebias (hid_t type)
herr_t H5Tset_ebias (hid_t type, size_t
ebias)
ebias larger than the true exponent.
H5Tget_ebias() returns zero on failure which is
also a valid exponent bias, but the function is guaranteed to
succeed if H5Tget_precision() succeeds when
called with the same arguments.
H5T_norm_t H5Tget_norm (hid_t type)
herr_t H5Tset_norm (hid_t type, H5T_norm_t
norm)
H5T_NORM_MSBSET then the
mantissa is shifted left (if non-zero) until the first bit
after the radix point is set and the exponent is adjusted
accordingly. All bits of the mantissa after the radix
point are stored.
H5T_NORM_IMPLIED then the
mantissa is shifted left (if non-zero) until the first bit
after the radix point is set and the exponent is adjusted
accordingly. The first bit after the radix point is not stored
since it's always set.
H5T_NORM_NONE then the fractional
part of the mantissa is stored without normalizing it.
H5T_pad_t H5Tget_inpad (hid_t type)
herr_t H5Tset_inpad (hid_t type, H5T_pad_t
inpad)
H5T_PAD_ZERO if the internal
padding should always be set to zero, or H5T_PAD_ONE
if it should always be set to one.
H5Tget_inpad() returns H5T_PAD_ERROR
on failure which is a negative value (successful return is
always non-negative).
Dates and times (class=H5T_TIME) are stored as
character strings in one of the ISO-8601 formats like
"1997-12-05 16:25:30"; as character strings using the
Unix asctime(3) format like "Thu Dec 05 16:25:30 1997";
as an integer value by juxtaposition of the year, month, and
day-of-month, hour, minute and second in decimal like
19971205162530; as an integer value in Unix time(2)
format; or other variations.
Fixed-length character string types are used to store textual
information. The offset property of a string is
always zero and the precision property is eight
times as large as the value returned by
H5Tget_size() (since precision is measured in bits
while size is measured in bytes). Both properties are
read-only.
H5T_cset_t H5Tget_cset (hid_t type)
herr_t H5Tset_cset (hid_t type, H5T_cset_t
cset)
H5T_CSET_ASCII.
H5T_str_t H5Tget_strpad (hid_t type)
herr_t H5Tset_strpad (hid_t type, H5T_str_t
strpad)
H5T_STR_NULLTERM
H5T_STR_NULLPAD
H5T_STR_NULLPAD
string will truncate but not null terminate. Conversion
from a short value to a longer value will append null
characters as with H5T_STR_NULLTERM.
H5T_STR_SPACEPAD
H5T_STR_NULLPAD except the padding character
is a space instead of a null.
H5Tget_strpad() returns
H5T_STR_ERROR on failure, a negative value (all
successful return values are non-negative).
Converting a bit field (class=H5T_BITFIELD) from
one type to another simply copies the significant bits. If the
destination is smaller than the source then bits are truncated.
Otherwise new bits are filled according to the msb
padding type.
H5T_NATIVE_CHAR and H5T_NATIVE_UCHAR
datatypes are actually numeric data (1-byte integers). If the
application wishes to store character data, then an HDF5
string datatype should be derived from
H5T_C_S1 instead.
unsigned char s[256] is
either an array of numeric data, a single character string
with at most 255 characters, or an array of 256 characters,
depending entirely on usage. For uniformity with the
other H5T_NATIVE_ types, HDF5 uses the
numeric interpretation of H5T_NATIVE_CHAR
and H5T_NATIVE_UCHAR.
unsigned char s[256] data as an
array of integer values, use the HDF5 datatype
H5T_NATIVE_UCHAR and a data space that
describes the 256-element array. Some other application
that reads the data will then be able to read, say, a
256-element array of 2-byte integers and HDF5 will
perform the numeric translation.
To store unsigned char s[256] data as a
character string, derive a fixed length string datatype
from H5T_C_S1 by increasing its size to
256 characters. Some other application that reads the
data will be able to read, say, a space padded string
of 16-bit characters and HDF5 will perform the character
and padding translations.
hid_t s256 = H5Tcopy(H5T_C_S1);
H5Tset_size(s256, 256);
To store unsigned char s[256] data as
an array of 256 ASCII characters, use an
HDF5 data space to describe the array and derive a
one-character string type from H5T_C_S1.
Some other application will be able to read a subset
of the array as 16-bit characters and HDF5 will
perform the character translations.
The H5T_STR_NULLPAD is necessary because
if H5T_STR_NULLTERM were used
(the default) then the single character of storage
would be for the null terminator and no useful data
would actually be stored (unless the length were
incremented to more than one character).
hid_t s1 = H5Tcopy(H5T_C_S1);
H5Tset_strpad(s1, H5T_STR_NULLPAD);
char to
represent one-byte numeric data and does not make
character strings a first-class datatype.
HDF5 makes a distinction between integer and
character data and maps the C signed char
(H5T_NATIVE_CHAR) and
unsigned char (H5T_NATIVE_UCHAR)
datatypes to the HDF5 integer type class.
Opaque types (class=H5T_OPAQUE) provide the
application with a mechanism for describing data which cannot be
otherwise described by HDF5. The only properties associated with
opaque types are a size in bytes and an ASCII tag which is
manipulated with H5Tset_tag() and
H5Tget_tag() functions. The library contains no
predefined conversion functions but the application is free to
register conversions between any two opaque types or between an
opaque type and some other type.
A compound datatype is similar to a struct in C
or a common block in Fortran: it is a collection of one or more
atomic types or small arrays of such types. Each
member of a compound type has a name which is unique
within that type, and a byte offset that determines the first
byte (smallest byte address) of that member in a compound datum.
A compound datatype has the following properties:
H5T_class_t H5Tget_class (hid_t type)
H5T_COMPOUND. This property is read-only and is
defined when a datatype is created or copied (see
H5Tcreate() or H5Tcopy()).
size_t H5Tget_size (hid_t type)
int H5Tget_nmembers (hid_t type)
H5Tget_nmembers() returns -1 on failure.
char *H5Tget_member_name (hid_t type, unsigned
membno)
malloc() or the null pointer on failure. The
caller is responsible for freeing the memory returned by this
function.
size_t H5Tget_member_offset (hid_t type, unsigned
membno)
H5Tget_member_class()
succeeds when called with the same type and
membno arguments.
hid_t H5Tget_member_type (hid_t type, unsigned
membno)
H5Tclose() on that type.
Properties of members of a compound datatype are
defined when the member is added to the compound type (see
H5Tinsert()) and cannot be subsequently modified.
This makes it imposible to define recursive data structures.
6. Predefined Atomic Datatypes
The library predefines a modest number of datatypes having
names like H5T_arch_base where
arch is an architecture name and base is a
programming type name. New types can be derived from the
predifined types by copying the predefined type (see
H5Tcopy()) and then modifying the result.
| Architecture Name | Description |
|---|---|
IEEE |
This architecture defines standard floating point types in various byte orders. |
STD |
This is an architecture that contains semi-standard datatypes like signed two's complement integers, unsigned integers, and bitfields in various byte orders. |
UNIX |
Types which are specific to Unix operating systems are
defined in this architecture. The only type currently
defined is the Unix date and time types
(time_t). |
C |
Types which are specific to the C or Fortran
programming languages are defined in these
architectures. For instance, H5T_C_STRING
defines a base string type with null termination which
can be used to derive string types of other
lengths. |
NATIVE |
This architecture contains C-like datatypes for the
machine on which the library was compiled. The types
were actually defined by running the
H5detect program when the library was
compiled. In order to be portable, applications should
almost always use this architecture to describe things
in memory. |
CRAY |
Cray architectures. These are word-addressable, big-endian systems with non-IEEE floating point. |
INTEL |
All Intel and compatible CPU's including 80286, 80386, 80486, Pentium, Pentium-Pro, and Pentium-II. These are little-endian systems with IEEE floating-point. |
MIPS |
All MIPS CPU's commonly used in SGI systems. These are big-endian systems with IEEE floating-point. |
ALPHA |
All DEC Alpha CPU's, little-endian systems with IEEE floating-point. |
The base name of most types consists of a letter, a precision in bits, and an indication of the byte order. The letters are:
| B | Bitfield |
| D | Date and time |
| F | Floating point |
| I | Signed integer |
| R | References |
| S | Character string |
| U | Unsigned integer |
The byte order is a two-letter sequence:
| BE | Big endian |
| LE | Little endian |
| VX | Vax order |
Example |
Description |
|---|---|
H5T_IEEE_F64LE |
Eight-byte, little-endian, IEEE floating-point |
H5T_IEEE_F32BE |
Four-byte, big-endian, IEEE floating point |
H5T_STD_I32LE |
Four-byte, little-endian, signed two's complement integer |
H5T_STD_U16BE |
Two-byte, big-endian, unsigned integer |
H5T_UNIX_D32LE |
Four-byte, little-endian, time_t |
H5T_C_S1 |
One-byte, null-terminated string of eight-bit characters |
H5T_INTEL_B64 |
Eight-byte bit field on an Intel CPU |
H5T_CRAY_F64 |
Eight-byte Cray floating point |
H5T_STD_ROBJ |
Reference to an entire object in a file |
The NATIVE architecture has base names which don't
follow the same rules as the others. Instead, native type names
are similar to the C type names. Here are some examples:
Example |
Corresponding C Type |
|---|---|
H5T_NATIVE_CHAR |
char |
H5T_NATIVE_SCHAR |
signed char |
H5T_NATIVE_UCHAR |
unsigned char |
H5T_NATIVE_SHORT |
short |
H5T_NATIVE_USHORT |
unsigned short |
H5T_NATIVE_INT |
int |
H5T_NATIVE_UINT |
unsigned |
H5T_NATIVE_LONG |
long |
H5T_NATIVE_ULONG |
unsigned long |
H5T_NATIVE_LLONG |
long long |
H5T_NATIVE_ULLONG |
unsigned long long |
H5T_NATIVE_FLOAT |
float |
H5T_NATIVE_DOUBLE |
double |
H5T_NATIVE_LDOUBLE |
long double |
H5T_NATIVE_HSIZE |
hsize_t |
H5T_NATIVE_HSSIZE |
hssize_t |
H5T_NATIVE_HERR |
herr_t |
H5T_NATIVE_HBOOL |
hbool_t |
|
To create a 128-bit, little-endian signed integer type one could use the following (increasing the precision of a type automatically increases the total size):
|
|
To create an 80-byte null terminated string type one might do this (the offset of a character string is always zero and the precision is adjusted automatically to match the size):
|
A complete list of the datatypes predefined in HDF5 can be found in HDF5 Predefined Datatypes in the HDF5 Reference Manual.
Unlike atomic datatypes which are derived from other atomic datatypes, compound datatypes are created from scratch. First, one creates an empty compound datatype and specifies it's total size. Then members are added to the compound datatype in any order.
Usually a C struct will be defined to hold a data point in memory, and the offsets of the members in memory will be the offsets of the struct members from the beginning of an instance of the struct.
HOFFSET(s,m)
offsetof(s,m)
stddef.h does
exactly the same thing as the HOFFSET() macro.
Each member must have a descriptive name which is the key used to uniquely identify the member within the compound datatype. A member name in an HDF5 datatype does not necessarily have to be the same as the name of the member in the C struct, although this is often the case. Nor does one need to define all members of the C struct in the HDF5 compound datatype (or vice versa).
|
An HDF5 datatype is created to describe complex
numbers whose type is defined by the
|
Member alignment is handled by the HOFFSET
macro. However, data stored on disk does not require alignment,
so unaligned versions of compound data structures can be created
to improve space efficiency on disk. These unaligned compound
datatypes can be created by computing offsets by hand to
eliminate inter-member padding, or the members can be packed by
calling H5Tpack() (which modifies a datatype
directly, so it is usually preceded by a call to
H5Tcopy()):
|
This example shows how to create a disk version of a compound datatype in order to store data on disk in as compact a form as possible. Packed compound datatypes should generally not be used to describe memory as they may violate alignment constraints for the architecture being used. Note also that using a packed datatype for disk storage may involve a higher data conversion cost.
|
|
Compound datatypes that have a compound datatype member can be handled two ways. This example shows that the compound datatype can be flattened, resulting in a compound type with only atomic members.
|
|
However, when the
|
An HDF enumeration datatype is a 1:1 mapping between a set of symbols and a set of integer values, and an order is imposed on the symbols by their integer values. The symbols are passed between the application and library as character strings and all the values for a particular enumeration type are of the same integer type, which is not necessarily a native type.
Creation of an enumeration datatype resembles creation of a compound datatype: first an empty enumeration type is created, then members are added to the type, then the type is optionally locked.
hid_t H5Tcreate(H5T_class_t type_class,
size_t size)
H5T_ENUM and the second argument is the
size in bytes of the native integer on which the enumeration
type is based. If the architecture does not support a native
signed integer of the specified size then an error is
returned.
/* Based on a native signed short */ hid_t hdf_en_colors = H5Tcreate(H5T_ENUM, sizeof(short));
hid_t H5Tenum_create(hid_t base)
H5Tcreate() function. This
function is useful when creating an enumeration type based on
some non-native integer datatype, but it can be used for
native types as well.
/* Based on a native unsigned short */ hid_t hdf_en_colors_1 = H5Tenum_create(H5T_NATIVE_USHORT); /* Based on a MIPS 16-bit unsigned integer */ hid_t hdf_en_colors_2 = H5Tenum_create(H5T_MIPS_UINT16); /* Based on a big-endian 16-bit unsigned integer */ hid_t hdf_en_colors_3 = H5Tenum_create(H5T_STD_U16BE);
herr_t H5Tenum_insert(hid_t etype, const char
*symbol, void *value)
short val; H5Tenum_insert(hdf_en_colors, "RED", (val=0,&val)); H5Tenum_insert(hdf_en_colors, "GREEN", (val=1,&val)); H5Tenum_insert(hdf_en_colors, "BLUE", (val=2,&val)); H5Tenum_insert(hdf_en_colors, "WHITE", (val=3,&val)); H5Tenum_insert(hdf_en_colors, "BLACK", (val=4,&val));
herr_t H5Tlock(hid_t etype)
H5Tlock(hdf_en_colors);
Because an enumeration datatype is derived from an integer datatype, any operation which can be performed on integer datatypes can also be performed on enumeration datatypes. This includes:
H5Topen() |
H5Tcreate() |
H5Tcopy() |
H5Tclose() |
H5Tequal() |
H5Tlock() |
H5Tcommit() |
H5Tcommitted() |
H5Tget_class() |
H5Tget_size() |
H5Tget_order() |
H5Tget_pad() |
H5Tget_precision() |
H5Tget_offset() |
H5Tget_sign() |
H5Tset_size() |
H5Tset_order() |
H5Tset_precision() |
H5Tset_offset() |
H5Tset_pad() |
H5Tset_sign() |
In addition, the new function H5Tget_super() will
be defined for all datatypes that are derived from existing
types (currently just enumeration types).
hid_t H5Tget_super(hid_t type)
hid_t itype = H5Tget_super(hdf_en_colors); hid_t hdf_fr_colors = H5Tenum_create(itype); H5Tclose(itype); short val; H5Tenum_insert(hdf_fr_colors, "ouge", (val=0,&val)); H5Tenum_insert(hdf_fr_colors, "vert", (val=1,&val)); H5Tenum_insert(hdf_fr_colors, "bleu", (val=2,&val)); H5Tenum_insert(hdf_fr_colors, "blanc", (val=3,&val)); H5Tenum_insert(hdf_fr_colors, "noir", (val=4,&val)); H5Tlock(hdf_fr_colors);
A small set of functions is available for querying properties of an enumeration type. These functions are likely to be used by browsers to display datatype information.
int H5Tget_nmembers(hid_t etype)
char *H5Tget_member_name(hid_t etype, unsigned
membno)
H5Tget_nmembers(). The members are stored in no
particular order. This function is already implemented for
compound datatypes. If an error occurs then the null pointer
is returned. The return value should be freed by calling
free().
herr_t H5Tget_member_value(hid_t etype, unsigned
membno, void *value/*out*/)
H5Tget_member_name()). The value returned
is in the domain of the underlying integer
datatype which is often a native integer type. The
application should ensure that the memory pointed to by
value is large enough to contain the result (the size
can be obtained by calling H5Tget_size() on
either the enumeration type or the underlying integer type
when the type is not known by the C compiler.
int n = H5Tget_nmembers(hdf_en_colors);
unsigned u;
for (u=0; u<(unsigned)n; u++) {
char *symbol = H5Tget_member_name(hdf_en_colors, u);
short val;
H5Tget_member_value(hdf_en_colors, u, &val);
printf("#%u %20s = %d\n", u, symbol, val);
free(symbol);
}
Output:
#0 BLACK = 4 #1 BLUE = 2 #2 GREEN = 1 #3 RED = 0 #4 WHITE = 3
In addition to querying about the enumeration type properties, an application may want to make queries about enumerated data. These functions perform efficient mappings between symbol names and values.
herr_t H5Tenum_valueof(hid_t etype, const char
*symbol, void *value/*out*/)
herr_t H5Tenum_nameof(hid_t etype, void
*value, char *symbol, size_t
size)
short data[1000] = {4, 2, 0, 0, 5, 1, ...};
int i;
char symbol[32];
for (i=0; i<1000; i++) {
if (H5Tenum_nameof(hdf_en_colors, data+i, symbol,
sizeof symbol))<0) {
if (symbol[0]) {
strcpy(symbol+sizeof(symbol)-4, "...");
} else {
strcpy(symbol, "UNKNOWN");
}
}
printf("%d %s\n", data[i], symbol);
}
printf("}\n");
Output:
4 BLACK 2 BLUE 0 RED 0 RED 5 UNKNOWN 1 GREEN ...
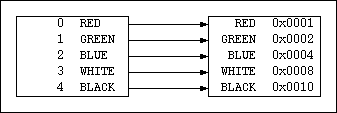
Enumerated data can be converted from one type to another provided the destination enumeration type contains all the symbols of the source enumeration type. The conversion operates by matching up the symbol names of the source and destination enumeration types to build a mapping from source value to destination value. For instance, if we are translating from an enumeration type that defines a sequence of integers as the values for the colors to a type that defines a different bit for each color then the mapping might look like this:
That is, a source value of 2 which corresponds to
BLUE would be mapped to 0x0004. The
following code snippet builds the second datatype, then
converts a raw data array from one datatype to another, and
then prints the result.
/* Create a new enumeration type */
short val;
hid_t bits = H5Tcreate(H5T_ENUM, sizeof val);
H5Tenum_insert(bits, "RED", (val=0x0001,&val));
H5Tenum_insert(bits, "GREEN", (val=0x0002,&val));
H5Tenum_insert(bits, "BLUE", (val=0x0004,&val));
H5Tenum_insert(bits, "WHITE", (val=0x0008,&val));
H5Tenum_insert(bits, "BLACK", (val=0x0010,&val));
/* The data */
short data[6] = {1, 4, 2, 0, 3, 5};
/* Convert the data from one type to another */
H5Tconvert(hdf_en_colors, bits, 5, data, NULL, plist_id);
/* Print the data */
for (i=0; i<6; i++) {
printf("0x%04x\n", (unsigned)(data[i]));
}
Output:
0x0002 0x0010 0x0004 0x0001 0x0008 0xffff
If the source data stream contains values which are not in the
domain of the conversion map then an overflow exception is
raised within the library, causing the application defined
overflow handler to be invoked (see
H5Tset_overflow()). If no overflow handler is
defined then all bits of the destination value will be set.
The HDF library will not provide conversions between enumerated data and integers although the application is free to do so (this is a policy we apply to all classes of HDF datatypes). However, since enumeration types are derived from integer types it is permissible to treat enumerated data as integers and perform integer conversions in that context.
Symbol order is determined by the integer values associated
with each symbol. When the integer datatype is a native type,
testing the relative order of two symbols is an easy process:
simply compare the values of the symbols. If only the symbol
names are available then the values must first be determined by
calling H5Tenum_valueof().
short val1, val2; H5Tenum_valueof(hdf_en_colors, "WHITE", &val1); H5Tenum_valueof(hdf_en_colors, "BLACK", &val2); if (val1 < val2) ...
When the underlying integer datatype is not a native type then
the easiest way to compare symbols is to first create a similar
enumeration type that contains all the same symbols but has a
native integer type (HDF type conversion features can be used to
convert the non-native values to native values). Once we have a
native type we can compare symbol order as just described. If
foreign is some non-native enumeration type then a
native type can be created as follows:
int n = H5Tget_nmembers(foreign);
hid_t itype = H5Tget_super(foreign);
void *val = malloc(n * MAX(H5Tget_size(itype), sizeof(int)));
char *name = malloc(n * sizeof(char*));
unsigned u;
/* Get foreign type information */
for (u=0; u<(unsigned)n; u++) {
name[u] = H5Tget_member_name(foreign, u);
H5Tget_member_value(foreign, u,
(char*)val+u*H5Tget_size(foreign));
}
/* Convert integer values to new type */
H5Tconvert(itype, H5T_NATIVE_INT, n, val, NULL, plist_id);
/* Build a native type */
hid_t native = H5Tenum_create(H5T_NATIVE_INT);
for (i=0; i<n; i++) {
H5Tenum_insert(native, name[i], ((int*)val)[i]);
free(name[i]);
}
free(name);
free(val);
It is also possible to convert enumerated data to a new type
that has a different order defined for the symbols. For
instance, we can define a new type, reverse that
defines the same five colors but in the reverse order.
short val;
int i;
char sym[8];
short data[5] = {0, 1, 2, 3, 4};
hid_t reverse = H5Tenum_create(H5T_NATIVE_SHORT);
H5Tenum_insert(reverse, "BLACK", (val=0,&val));
H5Tenum_insert(reverse, "WHITE", (val=1,&val));
H5Tenum_insert(reverse, "BLUE", (val=2,&val));
H5Tenum_insert(reverse, "GREEN", (val=3,&val));
H5Tenum_insert(reverse, "RED", (val=4,&val));
/* Print data */
for (i=0; i<5; i++) {
H5Tenum_nameof(hdf_en_colors, data+i, sym, sizeof sym);
printf ("%d %s\n", data[i], sym);
}
puts("Converting...");
H5Tconvert(hdf_en_colors, reverse, 5, data, NULL, plist_id);
/* Print data */
for (i=0; i<5; i++) {
H5Tenum_nameof(reverse, data+i, sym, sizeof sym);
printf ("%d %s\n", data[i], sym);
}
Output:
0 RED 1 GREEN 2 BLUE 3 WHITE 4 BLACK Converting... 4 RED 3 GREEN 2 BLUE 1 WHITE 0 BLACK
The order that members are inserted into an enumeration type is
unimportant; the important part is the associations between the
symbol names and the values. Thus, two enumeration datatypes
will be considered equal if and only if both types have the same
symbol/value associations and both have equal underlying integer
datatypes. Type equality is tested with the
H5Tequal() function.
enum TypeAlthough HDF enumeration datatypes are similar to C
enum datatypes, there are some important
differences:
| Difference | Motivation/Implications |
|---|---|
| Symbols are unquoted in C but quoted in HDF. | This allows the application to manipulate symbol names in ways that are not possible with C. |
| The C compiler automatically replaces all symbols with their integer values but HDF requires explicit calls to do the same. | C resolves symbols at compile time while HDF resolves symbols at run time. |
| The mapping from symbols to integers is N:1 in C but 1:1 in HDF. | HDF can translate from value to name
uniquely and large switch statements are
not necessary to print values in human-readable
format. |
A symbol must appear in only one C
enum type but may appear in multiple HDF
enumeration types. |
The translation from symbol to value in HDF requires the datatype to be specified while in C the datatype is not necessary because it can be inferred from the symbol. |
| The underlying integer value is always a native integer in C but can be a foreign integer type in HDF. | This allows HDF to describe data that might reside on a foreign architecture, such as data stored in a file. |
| The sign and size of the underlying integer datatype is chosen automatically by the C compiler but must be fully specified with HDF. | Since HDF doesn't require finalization of a datatype, complete specification of the type must be supplied before the type is used. Requiring that information at the time of type creation was a design decision to simplify the library. |
The examples below use the following C datatypes:
|
An HDF enumeration datatype can be created from a C
enum type simply by passing pointers to the C
enum values to H5Tenum_insert(). For
instance, to create HDF types for the c_en_colors
type shown above:
|
Occassionally two applicatons wish to exchange data but they
use different names for the constants they exchange. For
instance, an English and a Spanish program may want to
communicate color names although they use different symbols in
the C enum definitions. The communication is still
possible although the applications must agree on common terms
for the colors. The following example shows the Spanish code to
read the values assuming that the applications have agreed that
the color information will be exchanged using Enlish color
names:
|
Since symbol ordering is completely determined by the integer values
assigned to each symbol in the enum definition,
ordering of enum symbols cannot be preserved across
files like with HDF enumeration types. HDF can convert from one
application's integer values to the other's so a symbol in one
application's C enum gets mapped to the same symbol
in the other application's C enum, but the relative
order of the symbols is not preserved.
For example, an application may be defined to use the
definition of c_en_colors defined above where
WHITE is less than BLACK, but some
other application might define the colors in some other
order. If each application defines an HDF enumeration type based
on that application's C enum type then HDF will
modify the integer values as data is communicated from one
application to the other so that a RED value
in the first application is also a RED value in the
other application.
A case of this reordering of symbol names was also shown in the
previous code snippet (as well as a change of language), where
HDF changed the integer values so 0 (RED) in the
input file became 4 (ROJO) in the data
array. In the input file, WHITE was less than
BLACK; in the application the opposite is true.
In fact, the ability to change the order of symbols is often convenient when the enumeration type is used only to group related symbols that don't have any well defined order relationship.
The HDF enumeration type conversion features can also be used
to provide internationalization of debugging output. A program
written with the c_en_colors datatype could define
a separate HDF datatype for languages such as English, Spanish,
and French and cast the enumerated value to one of these HDF
types to print the result.
|
The main goal of enumeration types is to provide communication of enumerated data using symbolic equivalence. That is, a symbol written to a dataset by one application should be read as the same symbol by some other application.
| Architecture Independence | Two applications shall be able to exchange enumerated data even when the underlying integer values have different storage formats. HDF accomplishes this for enumeration types by building them upon integer types. |
| Preservation of Order Relationship | The relative order of symbols shall be preserved between two applications that use equivalent enumeration datatypes. Unlike numeric values that have an implicit ordering, enumerated data has an explicit order defined by the enumeration datatype and HDF records this order in the file. |
| Order Independence | An application shall be able to change the relative ordering of the symbols in an enumeration datatype. This is accomplished by defining a new type with different integer values and converting data from one type to the other. |
| Subsets | An application shall be able to read enumerated data from an archived dataset even after the application has defined additional members for the enumeration type. An application shall be able to write to a dataset when the dataset contains a superset of the members defined by the application. Similar rules apply for in-core conversions between enumerated datatypes. |
| Targetable | An application shall be able to target a particular architecture or application when storing enumerated data. This is accomplished by allowing non-native underlying integer types and converting the native data to non-native data. |
| Efficient Data Transfer | An application that defines a file dataset that corresponds to some native C enumerated data array shall be able to read and write to that dataset directly using only Posix read and write functions. HDF already optimizes this case for integers, so the same optimization will apply to enumerated data. |
| Efficient Storage | Enumerated data shall be stored in a manner which is space efficient. HDF stores the enumerated data as integers and allows the application to chose the size and format of those integers. |
VL datatypes are useful to the scientific community in many different ways, some of which are listed below:
Value1: Object1, Object3, Object9
Value2: Object0, Object12, Object14, Object21, Object22
Value3: Object2
Value4: <none>
Value5: Object1, Object10, Object12
.
.
Feature1: Dataset1:Region, Dataset3:Region, Dataset9:Region
Feature2: Dataset0:Region, Dataset12:Region, Dataset14:Region,
Dataset21:Region, Dataset22:Region
Feature3: Dataset2:Region
Feature4: <none>
Feature5: Dataset1:Region, Dataset10:Region, Dataset12:Region
.
.
H5Dread to fail while reading in
VL datatype information if the memory required exceeds that which is available.
In this case, the H5Dread call will fail gracefully and any
VL data which has been allocated prior to the memory shortage will be returned
to the system via the memory management routines detailed below.
It may be possible to design a partial read API function at a
later date, if demand for such a function warrants.
HDF5 has native VL strings for each language API, which are stored the
same way on disk, but are exported through each language API in a natural way
for that language. When retrieving VL strings from a dataset, users may choose
to have them stored in memory as a native VL string or in HDF5's hvl_t
struct for VL datatypes.
VL strings may be created in one of two ways: by creating a VL datatype with
a base type of H5T_NATIVE_ASCII, H5T_NATIVE_UNICODE,
etc., or by creating a string datatype and setting its length to
H5T_VARIABLE. The second method is used to access
native VL strings in memory. The library will convert between the two types,
but they are stored on disk using different datatypes and have different
memory representations.
Multi-byte character representations, such as UNICODE or wide characters in C/C++, will need the appropriate character and string datatypes created so that they can be described properly through the datatype API. Additional conversions between these types and the current ASCII characters will also be required.
Variable-width character strings (which might be compressed data or some other encoding) are not currently handled by this design. We will evaluate how to implement them based on user feedback.
H5Tvlen_create() function
as follows:
H5Tvlen_create(hid_t base_type_id);
The base datatype will be the datatype that the sequence is composed of, characters for character strings, vertex coordinates for polygon lists, etc. The base datatype specified for the VL datatype can be of any HDF5 datatype, including another VL datatype, a compound datatype, or an atomic datatype.
H5Tget_super() function, described in the H5T documentation.
H5Dread may need
to allocate to store VL data while reading the data, the
H5Dget_vlen_size() function is provided:
H5Dget_vlen_buf_size(hid_t dataset_id,
hid_t type_id,
hid_t space_id,
hsize_t *size)
This routine checks the number of bytes required to store the VL data from
the dataset, using the space_id for the selection in the dataset
on disk and the type_id for the memory representation of the
VL data in memory. The *size value is modified according to
how many bytes are required to store the VL data in memory.
H5Dread and H5Dwrite functions
with the dataset transfer property list.
Default memory management is set by using H5P_DEFAULT
for the dataset transfer property list identifier.
If H5P_DEFAULT is used with H5Dread,
the system malloc and free calls
will be used for allocating and freeing memory.
In such a case, H5P_DEFAULT should also be passed
as the property list identifier to H5Dvlen_reclaim.
The rest of this subsection is relevant only to those who choose not to use default memory management.
The user can choose whether to use the
system malloc and free calls or
user-defined, or custom, memory management functions.
If user-defined memory management functions are to be used,
the memory allocation and free routines must be defined via
H5Pset_vlen_mem_manager(), as follows:
H5Pset_vlen_mem_manager(hid_t plist_id,
H5MM_allocate_t alloc,
void *alloc_info,
H5MM_free_t free,
void *free_info)
The alloc and free parameters
identify the memory management routines to be used.
If the user has defined custom memory management routines,
alloc and/or free should be set to make
those routine calls (i.e., the name of the routine is used as
the value of the parameter);
if the user prefers to use the system's malloc
and/or free, the alloc and
free parameters, respectively, should be set to
NULL
The prototypes for the user-defined functions would appear as follows:
typedef void
*(*H5MM_allocate_t)(size_t size,
void *info) ;
typedef void
(*H5MM_free_t)(void *mem,
void *free_info) ;
The alloc_info and free_info parameters can be
used to pass along any required information to the user's memory management
routines.
In summary, if the user has defined custom memory management
routines, the name(s) of the routines are passed in the
alloc and free parameters and the
custom routines' parameters are passed in the
alloc_info and free_info parameters.
If the user wishes to use the system malloc and
free functions, the alloc and/or
free parameters are set to NULL
and the alloc_info and free_info
parameters are ignored.
H5Dvlen_reclaim() function call, as follows:
H5Dvlen_reclaim(hid_t type_id,
hid_t space_id,
hid_t plist_id,
void *buf);
The type_id must be the datatype stored in the buffer,
space_id describes the selection for the memory buffer
to free the VL datatypes within,
plist_id is the dataset transfer property list which
was used for the I/O transfer to create the buffer, and
buf is the pointer to the buffer to free the VL memory within.
The VL structures (hvl_t) in the user's buffer are
modified to zero out the VL information after it has been freed.
If nested VL datatypes were used to create the buffer, this routine frees them from the bottom up, releasing all the memory without creating memory leaks.
0 10 20 30
11 21 31
22 32
33
Each element of the VL datatype is of H5T_NATIVE_UINT type.
The array is stored in the dataset and then read back into memory. Default memory management routines are used for writing the VL data. Custom memory management routines are used for reading the VL data and reclaiming memory space.
#include <hdf5.h>
#define FILE "vltypes.h5"
#define MAX(X,Y) ((X)>(Y)?(X):(Y))
/* 1-D dataset with fixed dimensions */
#define SPACE_NAME "Space"
#define SPACE_RANK 1
#define SPACE_DIM 4
void *vltypes_alloc_custom(size_t size, void *info);
void vltypes_free_custom(void *mem, void *info);
/****************************************************************
**
** vltypes_alloc_custom(): VL datatype custom memory
** allocation routine. This routine just uses malloc to
** allocate the memory and increments the amount of memory
** allocated.
**
****************************************************************/
void *vltypes_alloc_custom(size_t size, void *info)
{
void *ret_value=NULL; /* Pointer to return */
int *mem_used=(int *)info; /* Get the pointer to the memory used */
size_t extra; /* Extra space needed */
/*
* This weird contortion is required on the DEC Alpha to keep the
* alignment correct.
*/
extra=MAX(sizeof(void *),sizeof(int));
if((ret_value=(void *)malloc(extra+size))!=NULL) {
*(int *)ret_value=size;
*mem_used+=size;
} /* end if */
ret_value=((unsigned char *)ret_value)+extra;
return(ret_value);
}
/******************************************************************
** vltypes_free_custom(): VL datatype custom memory
** allocation routine. This routine just uses free to
** release the memory and decrements the amount of memory
** allocated.
** ****************************************************************/
void vltypes_free_custom(void *_mem, void *info)
{
unsigned char *mem;
int *mem_used=(int *)info; /* Get the pointer to the memory used */
size_t extra; /* Extra space needed */
/*
* This weird contortion is required on the DEC Alpha to keep the
* alignment correct.
*/
extra=MAX(sizeof(void *),sizeof(int));
if(_mem!=NULL) {
mem=((unsigned char *)_mem)-extra;
*mem_used-=*(int *)mem;
free(mem);
} /* end if */
}
int main(void)
{
hvl_t wdata[SPACE_DIM]; /* Information to write */
hvl_t rdata[SPACE_DIM]; /* Information read in */
hid_t fid; /* HDF5 File IDs */
hid_t dataset; /* Dataset ID */
hid_t sid; /* Dataspace ID */
hid_t tid; /* Datatype ID */
hid_t xfer_pid; /* Dataset transfer property list ID */
hsize_t dims[] = {SPACE_DIM};
uint i,j; /* counting variables */
int mem_used=0; /* Memory used during allocation */
herr_t ret; /* Generic return value */
/*
* Allocate and initialize VL data to write
*/
for(i=0; i<SPACE_DIM; i++) {
wdata[i].p= (unsigned int *)malloc((i+1)*sizeof(unsigned int));
wdata[i].len=i+1;
for(j=0; j<(i+1); j++)
((unsigned int *)wdata[i].p)[j]=i*10+j;
} /* end for */
/*
* Create file.
*/
fid = H5Fcreate(FILE, H5F_ACC_TRUNC, H5P_DEFAULT, H5P_DEFAULT);
/*
* Create dataspace for datasets.
*/
sid = H5Screate_simple(SPACE_RANK, dims, NULL);
/*
* Create a datatype to refer to.
*/
tid = H5Tvlen_create (H5T_NATIVE_UINT);
/*
* Create a dataset.
*/
dataset=H5Dcreate(fid, "Dataset", tid, sid, H5P_DEFAULT);
/*
* Write dataset to disk.
*/
ret=H5Dwrite(dataset, tid, H5S_ALL, H5S_ALL, H5P_DEFAULT, wdata);
/*
* Change to the custom memory allocation routines for reading
* VL data
*/
xfer_pid=H5Pcreate(H5P_DATASET_XFER);
ret=H5Pset_vlen_mem_manager(xfer_pid, vltypes_alloc_custom,
&mem_used, vltypes_free_custom,
&mem_used);
/*
* Read dataset from disk. vltypes_alloc_custom and
* will be used to manage memory.
*/
ret=H5Dread(dataset, tid, H5S_ALL, H5S_ALL, xfer_pid, rdata);
/*
* Display data read in
*/
for(i=0; i<SPACE_DIM; i++) {
printf("%d-th element length is %d \n", i,
(unsigned) rdata[i].len);
for(j=0; j<rdata[i].len; j++) {
printf(" %d ",((unsigned int *)rdata[i].p)[j] );
}
printf("\n");
} /* end for */
/*
* Reclaim the read VL data. vltypes_free_custom will be used
* to reclaim the space.
*/
ret=H5Dvlen_reclaim(tid, sid, xfer_pid, rdata);
/*
* Reclaim the write VL data. C language free function will be
* used to reclaim space.
*/
ret=H5Dvlen_reclaim(tid, sid, H5P_DEFAULT, wdata);
/*
* Close Dataset
*/
ret = H5Dclose(dataset);
/*
* Close datatype
*/
ret = H5Tclose(tid);
/*
* Close disk dataspace
*/
ret = H5Sclose(sid);
/*
* Close dataset transfer property list
*/
ret = H5Pclose(xfer_pid);
/*
* Close file
*/
ret = H5Fclose(fid);
}
|
0-th element length is 1
0
1-th element length is 2
10 11
2-th element length is 3
20 21 22
3-th element length is 4
30 31 32 33
|
For further samples of VL datatype code, see the tests in test/tvltypes.c
in the HDF5 distribution.
H5T_ARRAY, allows the
construction of true, homogeneous, multi-dimensional arrays.
Since these are homogeneous arrays, each element of the array will be
of the same datatype, designated at the time the array is created.
Arrays can be nested. Not only is an array datatype used as an element of an HDF5 dataset, but the elements of an array datatype may be of any datatype, including another array datatype.
Array datatypes cannot be subdivided for I/O; the entire array must be transferred from one dataset to another.
Within the limitations outlined in the next paragraph, array datatypes may be N-dimensional and of any dimension size. Unlimited dimensions, however, are not supported. Functionality similar to unlimited dimension arrays is available through the use of variable-length datatypes.
The maximum number of dimensions, i.e., the maximum rank, of an array
datatype is specified by the HDF5 library constant H5S_MAX_RANK.
The minimum rank is 1 (one).
All dimension sizes must be greater than 0 (zero).
One array dataype may only be converted to another array datatype if the number of dimensions and the sizes of the dimensions are equal and the datatype of the first array's elements can be converted to the datatype of the second array's elements.
H5Tarray_create
| Creates an array datatype. | |
H5Tarray_create(
hid_t base,
int rank,
const hsize_t dims[/*rank*/],
const int perm[/*rank*/]
)
| ||
H5Tget_array_ndims
| Retrieves the rank of the array datatype. | |
H5Tget_array_ndims(
hid_t adtype_id
)
| ||
H5Tget_array_dims
| Retrieves the dimension sizes of the array datatype. | |
H5Tget_array_dims(
hid_t adtype_id,
hsize_t *dims[],
int *perm[]
)
| ||
The use of the array datatype class will not interfere with the use of existing compound datatypes. Applications may continue to read and write the older field arrays, but they will no longer be able to create array fields in newly-defined compound datatypes.
Existing array fields will be transparently mapped to array datatypes when they are read in.
#include <hdf5.h>
#define FILE "SDS_array_type.h5"
#define DATASETNAME "IntArray"
#define ARRAY_DIM1 5 /* array dimensions and rank */
#define ARRAY_DIM2 4
#define ARRAY_RANK 2
#define SPACE_DIM 10 /* dataset dimensions and rank */
#define RANK 1
int
main (void)
{
hid_t file, dataset; /* file and dataset handles */
hid_t datatype, dataspace; /* handles */
hsize_t sdims[] = {SPACE_DIM}; /* dataset dimensions */
hsize_t adims[] = {ARRAY_DIM1, ARRAY_DIM2}; /* array dimensions */
hsize_t adims_out[2];
herr_t status;
int data[SPACE_DIM][ARRAY_DIM1][ARRAY_DIM2]; /* data to write */
int k, i, j;
int array_rank_out;
/*
* Data and output buffer initialization.
*/
for (k = 0; k < SPACE_DIM; k++) {
for (j = 0; j < ARRAY_DIM1; j++) {
for (i = 0; i < ARRAY_DIM2; i++)
data[k][j][i] = k;
}
}
/*
* Create a new file using H5F_ACC_TRUNC access,
* default file creation properties, and default file
* access properties.
*/
file = H5Fcreate(FILE, H5F_ACC_TRUNC, H5P_DEFAULT, H5P_DEFAULT);
/*
* Describe the size of the array and create the data space for fixed
* size dataset.
*/
dataspace = H5Screate_simple(RANK, sdims, NULL);
/*
* Define array datatype for the data in the file.
*/
datatype = H5Tarray_create(H5T_NATIVE_INT, ARRAY_RANK, adims, NULL);
/*
* Create a new dataset within the file using defined dataspace and
* datatype and default dataset creation properties.
*/
dataset = H5Dcreate(file, DATASETNAME, datatype, dataspace,
H5P_DEFAULT);
/*
* Write the data to the dataset using default transfer properties.
*/
status = H5Dwrite(dataset, datatype, H5S_ALL, H5S_ALL,
H5P_DEFAULT, data);
/*
* Close/release resources.
*/
H5Sclose(dataspace);
H5Tclose(datatype);
H5Dclose(dataset);
/*
* Reopen dataset, and return information about its datatype.
*/
dataset = H5Dopen(file, DATASETNAME);
datatype = H5Dget_type(dataset);
array_rank_out = H5Tget_array_ndims(datatype);
status = H5Tget_array_dims(datatype, adims_out, NULL);
printf(" Array datatype rank is %d \n", array_rank_out);
printf(" Array dimensions are %d x %d \n", (int)adims_out[0],
(int)adims_out[1]);
H5Tclose(datatype);
H5Dclose(dataset);
H5Fclose(file);
return 0;
}
|
If a file has lots of datasets which have a common datatype, then the file could be made smaller by having all the datasets share a single datatype. Instead of storing a copy of the datatype in each dataset object header, a single datatype is stored and the object headers point to it. The space savings is probably only significant for datasets with a compound datatype, since the atomic datatypes can be described with just a few bytes anyway.
To create a bunch of datasets that share a single datatype just create the datasets with a committed (named) datatype.
|
To create two datasets that share a common datatype one just commits the datatype, giving it a name, and then uses that datatype to create the datasets.
And to create two additional datasets later which share the same type as the first two datasets:
|
The library is capable of converting data from one type to another and does so automatically when reading or writing the raw data of a dataset, attribute data, or fill values. The application can also change the type of data stored in an array.
In order to insure that data conversion exceeds disk I/O rates, common data conversion paths can be hand-tuned and optimized for performance. The library contains very efficient code for conversions between most native datatypes and a few non-native datatypes, but if a hand-tuned conversion function is not available, then the library falls back to a slower but more general conversion function. The application programmer can define additional conversion functions when the libraries repertoire is insufficient. In fact, if an application does define a conversion function which would be of general interest, we request that the function be submitted to the HDF5 development team for inclusion in the library.
Note: The HDF5 library contains a deliberately limited set of conversion routines. It can convert from one integer format to another, from one floating point format to another, and from one struct to another. It can also perform byte swapping when the source and destination types are otherwise the same. The library does not contain any functions for converting data between integer and floating point formats. It is anticipated that some users will find it necessary to develop float to integer or integer to float conversion functions at the application level; users are invited to submit those functions to be considered for inclusion in future versions of the library.
A conversion path contains a source and destination datatype and each path contains a hard conversion function and/or a soft conversion function. The only difference between hard and soft functions is the way in which the library chooses which function applies: A hard function applies to a specific conversion path while a soft function may apply to multiple paths. When both hard and soft functions apply to a conversion path, then the hard function is favored and when multiple soft functions apply, the one defined last is favored.
A data conversion function is of type H5T_conv_t,
which is defined as follows:
typedef herr_t (*H5T_conv_t) (hid_t src_id,
hid_t dst_id,
H5T_cdata_t *cdata,
hsize_t nelmts,
size_t buf_stride,
size_t bkg_stride,
void *buffer,
void *bkg_buffer,
hid_t dset_xfer_plist);The conversion function is called with
the source and destination datatypes (src_id and
dst_id),
the path-constant data struct (cdata),
the number of instances of the datatype to convert (nelmts),
a conversion buffer (buffer) which initially contains
an array of data having the source type and on return will
contain an array of data having the destination type,
a temporary or background buffer (bkg_buffer,
see description of H5T_BKG_YES below),
conversion and background buffer strides (buf_stride and
bkg_stride) that indicate what data is to be converted, and
a dataset transfer properties list (dset_xfer_plist).
buf_stride and bkg_stride are in bytes and are related to the size of the datatype. If every data element is to be converted, the parameter's value is equal to the size of the datatype; if every other data element is to be converted, the parameter's value is equal to twice the size of the datatype; etc.
dset_xfer_plist may contain properties that are passed to the read and write calls. This parameter is currently used only with variable-length data.
bkg_buffer and bkg_stride are used only with compound datatypes.
The path-constant data struct, H5T_cdata_t,
is declared as follows:
typedef struct *H5T_cdata_t (H5T_cmd_t command,
H5T_bkg_t need_bkg,
hbool_t *recalc,
void *priv)The command field of the cdata argument
determines what happens within the conversion function. It's
values can be:
H5T_CONV_INIT
priv field of cdata (or private data can
be initialized later). It should also initialize the
need_bkg field described below. The buf
and background pointers will be null pointers.
H5T_CONV_CONV
priv field of cdata if it wasn't
initialize during the H5T_CONV_INIT command and
then convert nelmts instances of the
src_type to the dst_type. The
buffer serves as both input and output. The
background buffer is supplied according to the value
of the need_bkg field of cdata (the
values are described below).
H5T_CONV_FREE
cdata->priv pointer) should be freed and
set to null. All other pointer arguments are null, the
src_type and dst_type are invalid
(negative), and the nelmts argument is zero.
Whether a background buffer is supplied to a conversion
function, and whether the background buffer is initialized
depends on the value of cdata->need_bkg
which the conversion function should have initialized during the
H5T_CONV_INIT command. It can have one of these values:
H5T_BKG_NONE
H5T_BKG_TEMP
H5T_BKG_YES
The recalc field of cdata is set when the
conversion path table changes. It can be used by conversion
function that cache other conversion paths so they know when
their cache needs to be recomputed.
Once a conversion function is written it can be registered and unregistered with these functions:
herr_t H5Tregister(H5T_pers_t pers, const
char *name, hid_t src_type, hid_t
dest_type, H5T_conv_t func)
H5T_PERS_HARD) or soft
(H5T_PERS_SOFT) conversion depending on the value
of pers, displacing any previous conversions for all
applicable paths. The name is used only for
debugging but must be supplied. If pers is
H5T_PERS_SOFT then only the type classes of the
src_type and dst_type are used. For
instance, to register a general soft conversion function that
can be applied to any integer to integer conversion one could
say: H5Tregister(H5T_PERS_SOFT, "i2i", H5T_NATIVE_INT,
H5T_NATIVE_INT, convert_i2i). One special conversion
path called the "no-op" conversion path is always defined by
the library and used as the conversion function when no data
transformation is necessary. The application can redefine this
path by specifying a new hard conversion function with a
negative value for both the source and destination datatypes,
but the library might not call the function under certain
circumstances.
herr_t H5Tunregister (H5T_pers_t pers, const
char *name, hid_t src_type, hid_t
dest_type, H5T_conv_t func)
H5Tregister() with the added feature that any
(or all) may be wild cards. The
H5T_PERS_DONTCARE constant should be used to
indicate a wild card for the pers argument. The wild
card name is the null pointer or empty string, the
wild card for the src_type and dest_type
arguments is any negative value, and the wild card for the
func argument is the null pointer. The special no-op
conversion path is never removed by this function.
|
Here's an example application-level function that
converts Cray
The background argument is ignored since it's generally not applicable to atomic datatypes. |
|
The convesion function described in the previous example applies to more than one conversion path. Instead of enumerating all possible paths, we register it as a soft function and allow it to decide which paths it can handle.
This causes it to be consulted for any conversion from an integer type to another integer type. The first argument is just a short identifier which will be printed with the datatype conversion statistics. |
NOTE: The idea of a master soft list and being able to
query conversion functions for their abilities tries to overcome
problems we saw with AIO. Namely, that there was a dichotomy
between generic conversions and specific conversions that made
it very difficult to write a conversion function that operated
on, say, integers of any size and order as long as they don't
have zero padding. The AIO mechanism required such a function
to be explicitly registered (like
H5Tregister_hard()) for each an every possible
conversion path whether that conversion path was actually used
or not.